- Last Time: More on linear regression
- Today:
- Collect any optional assignments (chapter 13 review problems). You may
hand those in as late as noon Friday as a homework replacement.
- Re: your test grade: instead of counting the tests equally, I'll
count your
- Best
- Second best
- Average of best and worst.
- Questions on linear regression
(especially interpreting Minitab output)?
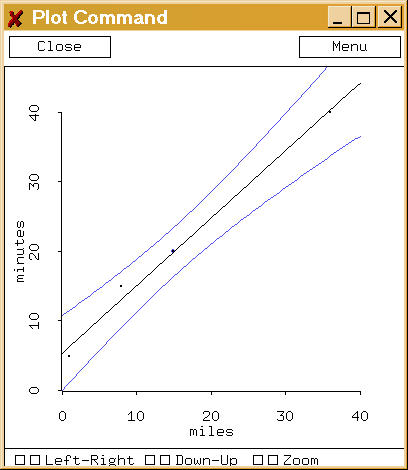
- Interpreting the scatterplot
- Interpreting the coefficients of the linear
equation (slope and y-intercept)
- Interpreting fit (R2)
- Hypothesis testing for the coefficients (observed
test statistic and p-value)
- Prediction and confidence intervals
- Extrapolation is risky! Interpolation is safer....
- Example:
- Review:
- Generalities/Logistics
- The final: 5/13, 10:10-12:10. Contact me with questions up
to the final:
- For the final you may use both sides of one-page of an
8.5x11 inch sheet of paper for
formulas and graphs, which you will turn in with your
test. I will provide a Z-table and t-table.
- Use complete sentences, and write in complete thoughts
when writing up a solution. Talk about the substantial
issues of the problem.
- Remember that your linear regression homework will count
as part of your final grade. You will attach it to the
test when you hand it in.
- Statistical basics
- Statistics is a means of teasing information out
of
data. Data is messy, noisy, full of errors. We'll make
mistakes in our conclusions, but seek to control them,
and predict the frequency of occurrence.
- Random variables (e.g. NKU heights) are our focus,
especially those which are quantititative,
which are distributed in various ways: e.g.
- normally (e.g. heights)
- uniformly (e.g. values on a fair die, or
coin tosses)
We often seek to characterize their
distributions (e.g. find the parameters which
lurk behind the distributions).
- In the terms of any example be able to identify
the population and parameter, versus the sample
and statistic which we hope sheds light on the
population and parameter.
- Be able to identify examples of descriptive
statistics (which simply characterize samples
of a random variables) and inferential
statistics (which seek to characterize the
underlying distribution via its parameters).
- Is the sample random and unbiased?
Remember that associated with inferential statistics
are confidence (and significance) levels. The price of
more confidence is a better (usually larger) sample.
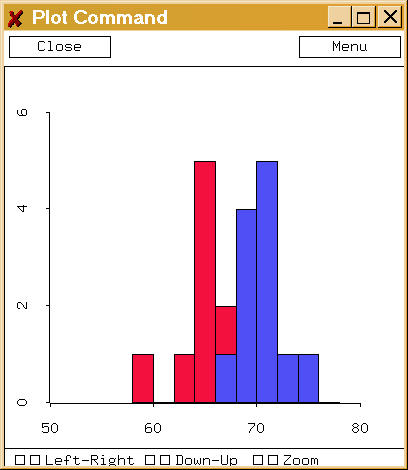
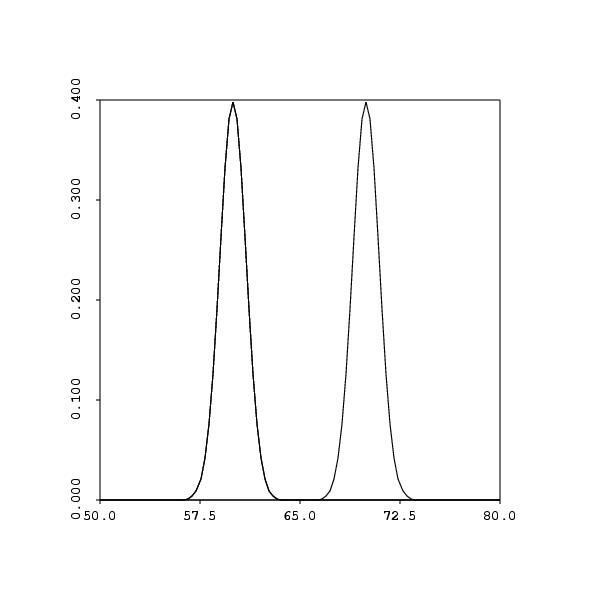
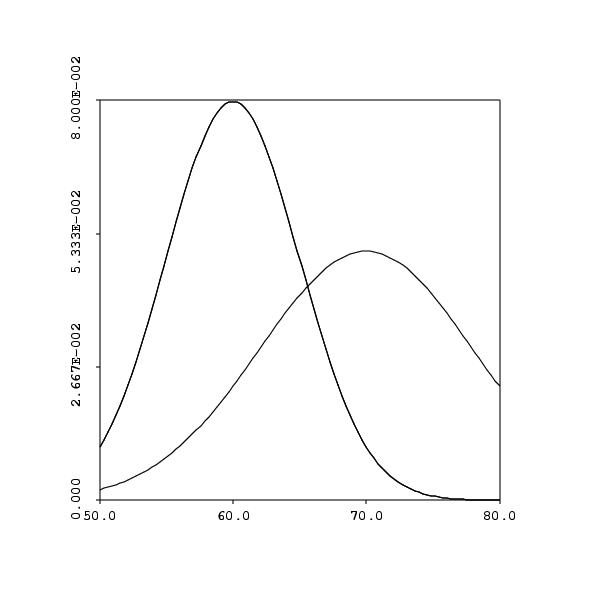
- Histograms - give us insight into the true distribution of
a random variable - e.g. NKU heights
- symmetry
- unimodal, bimodal, or multimodeal?
- What are typical (central) values?
- What are the largest and smallest values?
- Are there unusual or atypical values?
- Measures of central tendency of a random variable
- answer the question "Where is the data centered?"
- mean - average value (center of mass of histogram)
- sensitive to outliers
- median - middle value - insensitive to outliers
- mode - most common value (or class midpoint)
- Measures of spread of a random variable
- answer the question "How does the data 'deviate'
from the center?"
- range, variance, and standard deviation (square
root of the variance)
- Empirical rule (for bell-shaped distributions): 68/95/99
- Chebysheff's Theorem: the (conservative) 0/75/89 rule
- The normal distribution and probabilities
- Think of the normal distribution as the limiting case of a
histogram with an huge number of samples
- Know how to use the Z table of normal probabilities (p. 235, or
appendix B-8)
- Writing areas as probabilities (e.g. P(0 < Z < 2.17) is
the same as the value in the table on p. 235 for a Z
value of 2.17 - .4850)
- Using the Z table backwards - given an area, find the
value (or values) of Z associated.
- Sampling distributions (obtained using the central limit theorem):
- of a
mean (n>30? histogram relatively
normal-looking means we can get away with fewer)
- of a
proportion (np and n(1-p)>5?)
- Estimators
- point estimators
- unbiasedness
- consistency
- relatively efficient estimator
- interval estimators - generally the larger the sample size,
the smaller the interval -
e.g. CI for the mean
- Compute the sample size necessary to obtain a
fixed-sized interval estimator
- Hypothesis testing
- null and alternative hypotheses
- test statistic
- distribution of test statistic
- one- and two-tailed tests
- significance and confidence levels
- p-values - probability of values more extreme than
the calculated statistic
- rejection regions - region of extreme statistics
- Type I (reject true null) and Type II errors (fail
to reject false null)
- t-distribution
- Major issue: sample standard
deviation (s), rather than population
value (sigma).
- Major twist: "degrees of freedom" is now required.
- Looks like a normal, more so as the degrees of
freedom head for infinity
- Assure that the use of t is appropriate
The tests remain essentially the same, only the
distribution changes. We have to use a t-table rather
than a z-table.
- Test statistic and CI for a proportion p
- use normal statistics
- variance is related to the point estimate - we
need to use the point estimate phat in
the standard error formula for CI, but not for test.
- Difference in two means
- Independent samples
- Paired samples - reduces to a standard t-test of
the mean of the difference variable.
- New material:
- Difference in two proportions (section 13.6 -
e.g. the M&M experiments we conducted in class)
- Linear regression (interpreting Minitab output,
right along the lines of the homework
exercises):
- Interpreting the scatterplot
- Interpreting the coefficients of the linear
equation (slope and y-intercept)
- Interpreting R2
- hypothesis testing for the coefficients (observed test
statistic and p-value)
- prediction and confidence intervals (avoiding
extrapolation)
- Evaluations
- Next time: See you at the final!
Website maintained by Andy Long.
Comments appreciated.
{kind=link}
{kind=link}
{kind=link}
{kind=link}