Diagonalization of Symmetric Matrices
Summary
As we begin chapter seven, we should keep track of our specific objectives: we're interested in two goals:
Theorem 1: If A is symmetric, then any two eigenvectors from different eigenspaces are orthogonal.
Example: #13, p. 454
orthogonally diagonalizable: A matrix is orthogonally diagonalizable if there is an orthogonal matrix P and diagonal matrix D such that
![]()
Example: #22, p. 454
Theorem 2: ![]() is orthogonally diagonalizable if and only if
A is a symmetric matrix.
is orthogonally diagonalizable if and only if
A is a symmetric matrix.
The Spectral Theorem: Symmetric ![]() has the following
properties:
has the following
properties:
Example: #31, p. 455
Since ![]() , where p is an orthogonal matrix, we can write
, where p is an orthogonal matrix, we can write
![]()
the spectral decomposition of A. Each matrix ![]() is a projection matrix: the projection of vector x onto the
subspace spanned by
is a projection matrix: the projection of vector x onto the
subspace spanned by ![]() is given by
is given by
![]()
(the last part of the equation is one way of thinking of the projection that I've emphasized).
Example: #34, p. 455
The action of A as a linear transformation is well understood, therefore:
![]()
or
![]()
That is, we project x onto each basis vector, and then multiply each of these projections by the corresponding eigenvalue. Alternatively, if
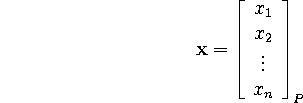
where P represents the basis composed of its columns, then
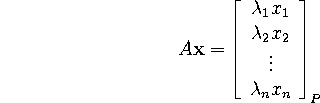
Neat!