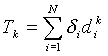
Data Requirements
spatial locations of cases and controls
Analysis
H0: cases and controls are sampled from a common spatial point distribution
Ha: the cases are spatially clustered relative to the controls
Test Statistic: The test statistic is the sum, over all cases, of the number of each case’s k nearest neighbors that also are cases. Define d i = 1 if observation i is a case and 0 if it is a control;
The expected value of the test statistic under the null hypothesis is
![]()
where N is the sample population size and
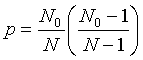
where N0 is the number of cases.
The variance is a fairly complex expression and is given in Cuzick and Edwards (1990). It can be used to calculate a z-score which is distributed as a normal deviate and can be used to evaluate significance.
When cases are clustered the nearest neighbor to a case will tend to be another case, and the test statistic will be large.
Output
The p-values from each row are combined using both the Bonferroni and Simes corrections
Upper and lower bounds on Tk are calculated when distance ties are encountered (Jacquez, 1994)
Map case and control locations
References
Cuzick, J. and Edwards, R. 1990. Spatial clustering for inhomogeneous populations. Journal of the Royal Statistical Society Series B, 52:73-104.
Jacquez, G.M. 1994. Cuzick and Edwards’ test when exact locations are unknown. American Journal of Epidemiology, 140:58-64.
Jacquez, G.M. 1994, User manual for Stat!: Statistical software for the clustering of health events, BioMedware, Ann Arbor, MI.