Webster R., et al. 1994. Kriging the Local Risk of a Rare Disease from a Register of Diagnoses. Geographical Analysis, 26:2, pp. 168-185.
Page 169: The first paragraph which starts on this page is a nice overview of the geostatistical scenerio.
Page 170: The authors make a point that I like to make: Talking about someone else's method, they say "[h]is method has similarities to kriging, but the latter is less arbitrary since it models the spatial correlation in the data for the estimation."
This is really the strong point of kriging - modelling spatial correlation means the method is less arbitrary than those which don't.
Page 172: we get a taste of the basis of geostatistical modelling - definition of the model, variogram, etc.
Page 173: I tried to replicate the results of Table 2, and did replicate the Poisson expected numbers, but could not replicate the binomial expected numbers. I tried using a negative binomial (a la Matui housing data of the end of the spatial statistics module), and got essentially the same numbers that the authors have for the binomial. I expect that they screwed up and meant the negative binomial.
If so, then we know how to interpret the results: the good fit of the negative binomial could suggest generalized or compound Poisson processes. The existence of spatial autocorrelation would tend to implicate apparent (compound) rather than true contagion, and thus clustering with a poisson parameter that varies over space.
Page 174: estimator of the variogram given; notes that "lags are incremented in steps in both distance and direction.... Where sampling has been irregular ... the lag must be divided into discrete increments.... [I]f the variation is isotropic or appears to be so then we can treat the lag as a scalar, h...." Otherwise we have to deal with the anisotropy....
I might mention that there are other, more robust, estimators of the variogram; even so, the estimator of (6) is by far the most common.
Page 177: they fit their model (which is not really among the most common of models - Whittle's) via weighted least squares.
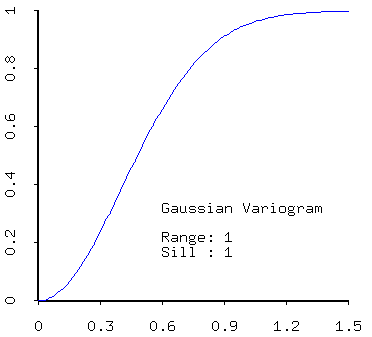
Note that "The lag distance at which the variogram reaches its sill, the range, is the limit of spatial dependence."
Page 178: Fig. 4, a graphical description of the standard parameters in variogram models. "...we can use the variogram to judge how much of the variation is spatially structured, that is, patterned, and what proportion is purely random at the working scale" (my emphasis).
Also, for unbounded variograms, "...for practical purposes we can take the lag at which [the variogram] reaches 95 percent of the sill as a limit" to the spatial correlation.
Kriging: "By kriging we take into account the correlated risks in nearby wards and thereby improve the estimates optimally. Usual practice is to compute kriged estimates at the nodes of a fine grid and to "contour" the resultant figure field."
Page 180: mention of cokriging, the multivariate form of kriging, which entails the modelling of "cross variograms" (also mentioned). We don't want to get into that here!
"Usually only the data nearest to x_0 carry appreciable weight, and so instead of solving the kriging equations what N equal to the total number of observations some much smaller number, usually between sixteen and twenty-five, is taken."
Page 182: "The standard error is smallest in the towns and cities where the data are most dense." What they call the standard error is usually called the kriging variance or estimation variance (or rather the square of it is).
Discussion and Conclusion: "...it appears that the correlation extends to some 50 kilometers", and a hypothesis consistent with this is explored: "[Barclay] suggests that [lymphoblastic leukemia] arises from children's being exposed to common diseases when they are somewhat older than their urban counterparts."
Carrat, F. and A. Valleron. Epidemiologic Mapping using the 'Kriging' Method: Application to an Influenza-like illness Epidemic in France. AJE, 135:11, pp. 1293-1300.
Page 1293: "Various 'smoothing and interpolation' techniques have been developed...: inverse distance-weighted methods...trend polynomials, and splines. These methods present two limitations: First, they fix tuning constants or make prior assumptions that do not take advantage of the spatial structure of the variable. Second, they do not allow for estimation of the error of interpolation."
Page 1294: "developed in 1971 in its original form by Matheron from an idea of D. G. Krige; hence the name 'kriging.'"
Again, mention of the intrinsic hypothesis; plus the goal of kriging: "A key property of kriging is that the semivariogram [aka variogram] function can be used to estimate the value of the process at unrecorded places from the neighboring sample values."
Page 1295: Again, the usual estimator of the semivariogram; "Clark suggests that a good choice for the lag h is 10 percent of the average sample spacing and that estimates of the semivariogram should be calculated to half the maximum distance between two sampling points."
"The spherical model is the most widely used...." Kind of ironic, given that it seems to be about the most ad hoc of any model, some of which are represented here.
"Lagrange multiplier": Who was Lagrange?
Page 1296: note the equation given for the estimation variance. It is computed from the weights obtained, and the right hand side of the kriging equations (i.e., it is about free once we have the estimate).
Discussion of the "jackknife" procedure (aka cross-validation), which they describe as a means to "verify the validity of all assumptions (the intrinsic hypothesis, choice of the semivariogram model)." They state that "[i]t is therefore advisable to perform [cross-validation] on the whole set of data, and on the set of data obtained after exclusion of the extreme values." Certainly many statisticians will look askance at this practice!
Page 1297: I don't like their model: any time I see one without a nugget I get uneasy. Looks to me like a Gaussian with a nugget might have been a better choice. They don't state how their model was calculated, but it looks like they only considered spherical models according to the caption to Figure 1.
They, too, interpret their range (174 km). The range is undoubtably the most interpretable parameter!
An important point: "Note that unlike in classical mapping methods based on distance, in the kriging method the weights may be negative." I say that kriging is "riskier" than the other methods: it will go out on a limb and predict something "outside of the kernel of the data" (that is, it may produce an estimate higher or lower than any data value - how brash!). Notice the negative weights in Table 1 of the next page.
Page 1298: Misreading of the intrinsic hypothesis: "The second `ordinary kriging' assumption concerns an intrinsic hypothesis, i.e., that there is no local trend in the early stage of an epidemic...." The intrinsic hypothesis is not about the data, and what actually happens in influenza: it is about the underlying random variables. I like to say that "there is what God could lay down, and then there is what she does lay down". The first is the random function; the second is a realization, of which you have a sample. The model, estimated from data, concerns the random function.
Page 1300: "Kriging also deals with the problem of missing data". "Since it relies on the spatial variability displayed by the actual data to be mapped, it provides the variance of the estimated values.... Error maps can then be used to decide where to introduce new sampling values - namely, at those places on the map where the standard error is judged to be too high." A proper use of the kriging variance.
{kind=link}
{kind=link}