- Your second homework set is returned. I just went ahead and graded them all. It wasn't that many problems, and I wanted to see what you're doing....
- #1: One thing our authors emphasize is the importance of not
truncating/rounding too soon. E.g. representing
as
(rather than as 2.718, say).
On p. 53, the authors suggest entering the value
rather than a standard approximation to
(e.g. 3.14159). That way, you get all the precision that the computer offers.
Some of you missed that we are interested in how the error in
propogates into error in
.
- #2: There is an analytical argument that needs to be made here: that the relative error is monotonic on the interval [1.3,1.5] (so that checking the endpoints is sufficient!).
- #5: Some folks got the picture wrong. We're not simply trying to
compute
. We're trying to use one approximation (for
) to obtain another.
(b) I was a little puzzled by the popular answer
.
The question in (a) was to find an approximation of
Jason got the idea.
- #6: Zach B. has this one.
- #7: Where does this particular
come from?
- #3, p. 14: some of you just skipped part (b) -- but that's the
most important part!
Let's look at a pretty quick and dirty solution that uses something we discussed last time.
- #1: One thing our authors emphasize is the importance of not
truncating/rounding too soon. E.g. representing
- Questions about things in general?
We're going to pick up again on chapter 2, and see how far we can get...
Section 2.1:
"The main idea is that the computer works with a finite subset of the reals known as machine numbers." (p. 33)
- Section 2.1: Positional Number Systems
I might have started this chapter with Figure 2.3, on page 41:
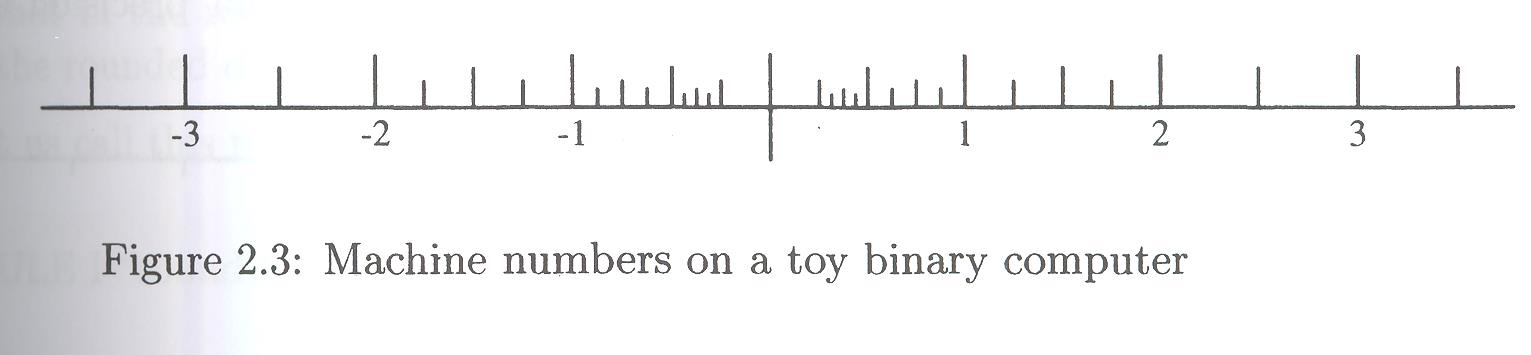
It gives a picture of machine numbers on a "toy binary computer". Section 2.1 makes a point about the need to consider other bases (other than 10). Among these other bases, the base 2 is probably the most important.
Question: why does base 2 figure so prominently in computer science?
There's a beautiful example here of how base 3 is used for tagging hogs:

Questions:
- I grabbed the image above off the interwebs, but I'd have liked a better one, that illustrates something in the book -- what would I have liked?
- What number in the litter is this pig?
I've asked you to write a base converter for homework. Do you know how to convert from a one base to another?
- Suppose, for example, that you want to convert from 10 to 2; how do you do that?
- Then, how do you convert from 2 to 10?
Let's try a few. What's
-
in base 2?
-
in base 10?
- One more, with a twist:
Section 2.2: Floating-Point Numbers
In this section the authors describe the manner in which numbers are stored in the computer. They focus on "floating-point numbers", which are represented by three parts:
- The sign of the number
- The position of the "radix" point (aka decimal point in base 10) -- we might say the "order of magnitude" of the base.
- The mantissa (the known digits)
Definition 2.1: A real number is said to be an n-digit number if it can be expressed as
Question: They then ask "What's an n-bit number?" (p. 39) What do you tell them?
Let's imagine that our machine has base-10 architecture, with
, and
. Then we know exactly which
numbers may be represented: numbers from
| Largest magnitude numbers | -9.999x109 | +9.999x109 |
| Smallest magnitude numbers | -1.000x10-9 | +1.000x10-9 |
Failure to include the denormalized numbers (that don't have a leading 1) leads to a gap around zero in this figure:
We see that the smallest positive number representable is 1/4. The smallest subdivision is 1/16. It seems that 4 may not be representable. What might be the toy machine representation architecture?
On the downside, if we allowed non-zero leading digits, then there would be redundant representations for many numbers (e.g. +1.000x10-9=+0.100x10-8)
Now, in reality, computations are usually done in base 2, and the IEEE standard for single precision and double precision are
| Single | Double | |
| Base | 2 | 2 |
| n | 24 | 53 |
| e | [-126:127] | [-1022:1023] |
Question: in each case, how many exponents are there in the exponent range? Of what significance are these numbers (or numbers close, rather...)?
Question: let's see if we can make sense of this system with this particular example:

Our authors describe the difference between precision and accuracy at this point: I think that it's best done graphically:

Section 2.3: Rounding
"The purpose of rounding in computation is to turn any real number into a machine number, preferably the nearest one." (p. 43)
But there are different ways to do it. You're no doubt familiar with rounding (but how do you handle ties -- that is, how do we round 19.5 to an integer?)). The authors suggest several strategies (p. 43):
- Rule 1: "round-to-even": if the digits following the nth digit are
- less than 500000....
then discard these digits - greater than 500000....
then discard these digits and add 1 to the nth digit - exactly equal to 500000....
then discard these digits and add 1 to the nth digit if it is odd.
"Round-to-even" because if nth digit is even, do nothing; add 1 if odd, making it even. All nth digits become even.
- less than 500000....
- Rule 2: "round-to-nearest, with round away from zero in case of a tie"
Same as Rule 1, except when exactly equal to 500000....
then round UP (away from zero).Inferior to Rule 1, as ever-so-slightly biased away from zero.
- Rule 3: chopping -- "round-to-zero" -- truncation.
Whatever comes after nth, just drop it.
Inferior to Rule 1, as slightly biased toward zero.
The biases are illustrated nicely in Figure 2.5, p. 45:
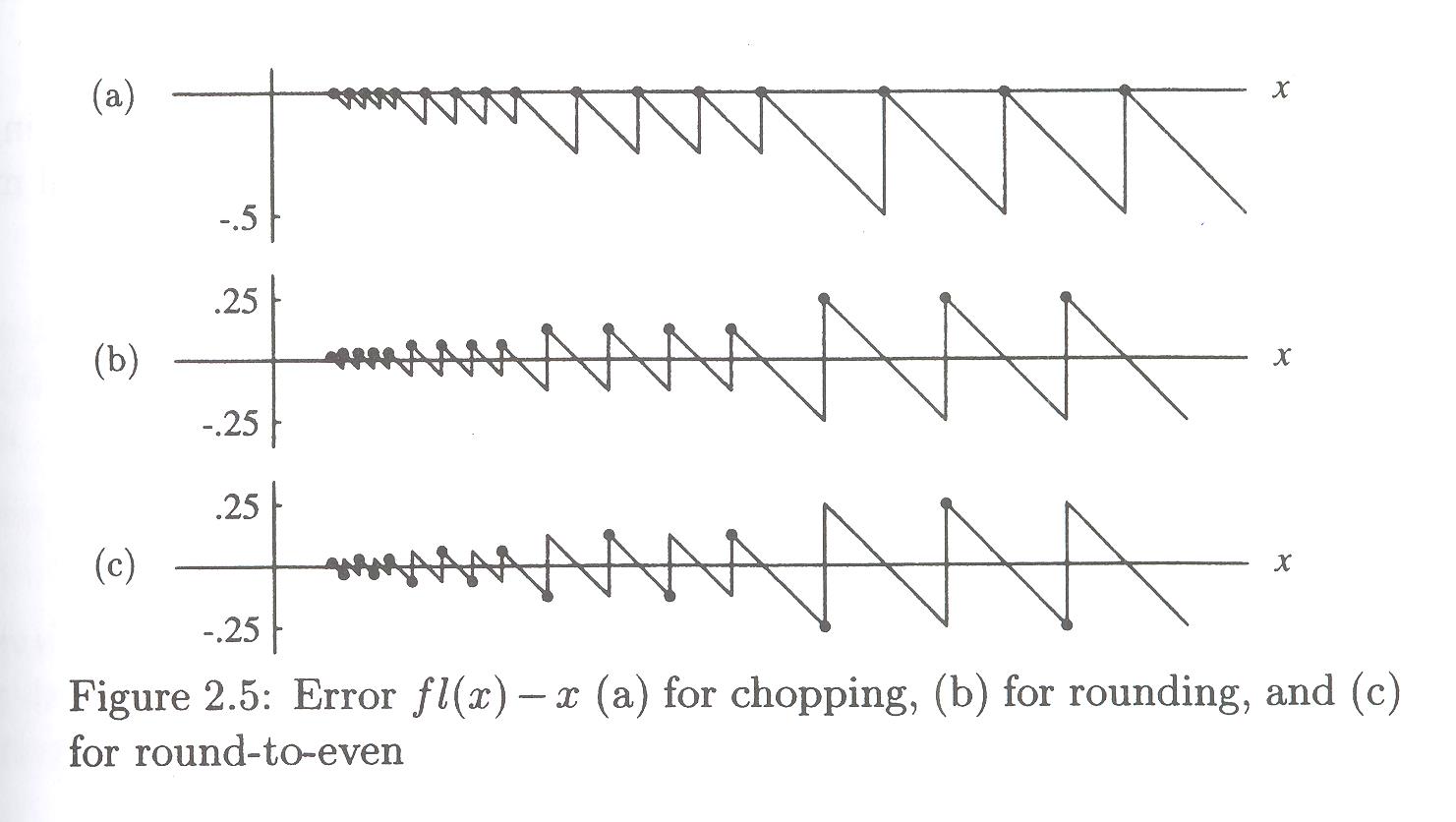
The chopping approximations are all under-estimates; the rounding methods give more balanced overs and unders; but the rounding alone has a bias for giving overestimates, which rounding-to-even balances out.
There is some vocabulary here with which we should be familiar: sometimes rounding results in
- overflow (
)
- underflow (below the smallest possible machine number)
- NaN (not a number)
Definitions:
- fl (float)
- converts real numbers into machine numbers
- A real number is said to be representable if
- it rounds to a machine number (neither overflow nor
underflow, nor NaN).
- relative representation error:
-
The authors make the case that
where
-
is the base, and
-
is the precision (number of decimals in the mantissa)
Section 2.4: Basic Operations
By "basic operations" the authors mean using standard arithmetic operations on machine numbers to produce machine numbers. There will be errors.
Let a and b be machine numbers, and let represent any of the standard
arithmetic operations. Then
I.e., to compute one of these binary operations with machine numbers,
you do the operation exactly, and then convert it to a machine
number with float (fl). We already know what this will cost:
we'll have a roundoff error of .
As we compute more complicated function, however, with one unary or binary operation after another, the errors continue to accumulate (as seen for example, in section 2.4.5, p. 54).
Examples:
- #1, p. 54: Assuming four digit floating-point arithmetic with
round-to-even rounding, perform the following computations:
(a) 0.6668+0.3334 (b) 1000.-0.05001 (c) 2.000*0.6667 (d) 25.00/16.00 - #8, p. 55
- #9, p. 56
Section 2.5: Numerical Instability
This section features several interesting examples of functions, some of them tremendously important, which are also extraordinarily sensitive to errors.
One of the main points of the section is that a "solution" to a problem may be technically correct, analytically correct, and yet poorly designed to produce good results in general.
Let's go through the example problem on pages 62-63. It's a simple calculation, but illustrates how the reasonable can go awry....
An excellent example is the quadratic formula. Many of you have memorized it as
We can imagine situations, however, for which this calculation may be dangerous. What do you notice?