- Your little assignment is returned (compute
a regression equation by hand for the Keeling
data). Several of you didn't recover the linear model that we
obtained in class with the Mathematica code. If not, you need
to hunt down the problem!
One problem is using the wrong equations, and sometimes the units will tell us that we have a problem. Paying attention to units pays!
- Also a reminder that your mini-projects #1 are due
today. Remember that this is a group project, and I just want
one report per group. These reports will be made available to
all, because we're going to next assemble all the towns into
one single model for all of Togo; so I'll need an electronic
copy to post.
Just get that to me by the end of the day.
If your group has any questions, feel free to stop by and talk to me!
- You have a new homework assignment, which is to fit a
linear model (including oscillation) to the more detailed Keeling data (due
next Friday). Details on the assignment page. This is a warm-up
for doing the same for another town in Togo. I've just received
the monthly temperatures, max and min. They, too, will show a
seasonal variation.
I'll be assigning groups and towns next Friday, after we discuss the fit to the Keeling data in class.
Hopefully you now understand vector and matrix notation, and a few important operations (e.g. transpose and inverse).
Matrices will be important in other models we consider.
- So we'll wrap up the linear algebra regression
diagnostics today. Our objective is to think about how
to evaluate a regression model.
- We'll check
the diagnostic results using Mathematica, to see that we get
the same diagnostics that Mathematica did using
LinearModelFit.
- Regression Diagnostics: Polya's "evaluate" step.
There are three things I always consider about a model:
- Graphical check of Fit and Residuals - is there a
pattern to the residuals? If so, we go back to
the model-building step....
- residual "errors" are supposed to be "iid" -- independent and identically distributed (and we hope for normally distributed).
- Hopefully the residuals are not clustered, nor wildly different in size, and,
- if you graph the residuals as a histogram, you get something resembling a normal distribution (bell-shaped curve).
- $R^2$: how much variation does my model explain?
- We break variance down into two parts: a fraction due to the model, and the residual.
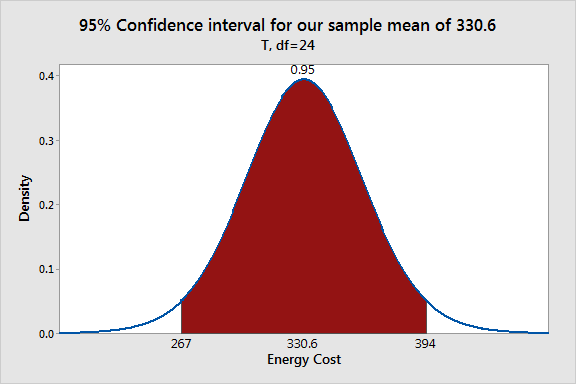
- Confidence intervals for parameters (essentially
equivalent to p-values, but perhaps more
informative).
The standard errors of the parameters pop out of the inverse matrix we compute, multiplied by the mean SSE. Once we have those, we have everything we need for confidence intervals.
We're often interested to know whether we can exclude a certain value from a confidence interval -- e.g., can we conclude that the slope parameter $b$ in a linear regression $y(x)=a+bx$ is not 0? If so, we conclude that there is a non-zero slope, and the model suggests that $x$ drives values up or down, depending on the sign of $b$.
- Graphical check of Fit and Residuals - is there a
pattern to the residuals? If so, we go back to
the model-building step....
- Then we'll start looking at some examples, including some
of the functions from the "Bestiary" which can be
linearized, meaning that we can use linear regression
to estimate their parameters.
- Keeling data -- Patrick's exponential model
Patrick proposed an exponential model for the Keeling data, but it is non-linear in the parameters: \[ y(t)=ae^{bt} \]
Yet we can still use linear regression to fit it: how so?
- Construct an exponential model to the Keeling data. How do we compare the exponential and linear model?
- How do we compare the exponential and quadratic model?
- Advertising expenditures
- Power model
- Exponential model
- How do they compare?
- Sea Anemone reaction time
- Keeling data -- Patrick's exponential model
- Links:
- Using Mathematica's LinearModelFit to find linear
models that fit Stewart's Keeling data
- An extract from Curve
Fitting via the Criterion of Least Squares, by John
Alexander. A bit old-fashioned, but it's got all the
major ideas, and some nice examples.
Alexander also illustrates that one cannot simply invert the regression equation $y=a+bx$ to get the regression equation $x=\frac{y-a}{b}$. So it really matters in linear regression which variable is considered "independent" and which is considered "dependent".
- My linear algebra derivation.
- Using Mathematica's LinearModelFit to find linear
models that fit Stewart's Keeling data
